

Updates to SpruceID’s Developer Documentation
We've revamped our developer documentation and mobile SDKs to simplify integrating verifiable digital credentials into your apps.
At Spruce, our core drive revolves around a world where users have full control over their identity and data in their digital interactions. However, this shouldn’t be at the expense of user experience in applications, or user experience around the control of said information.
To start with, let’s take a look at the web as it stands now. Current regulations governing user data protections have left us in the following state, which includes an illusion of choice - namely that one can leave, but not in any meaningful way.
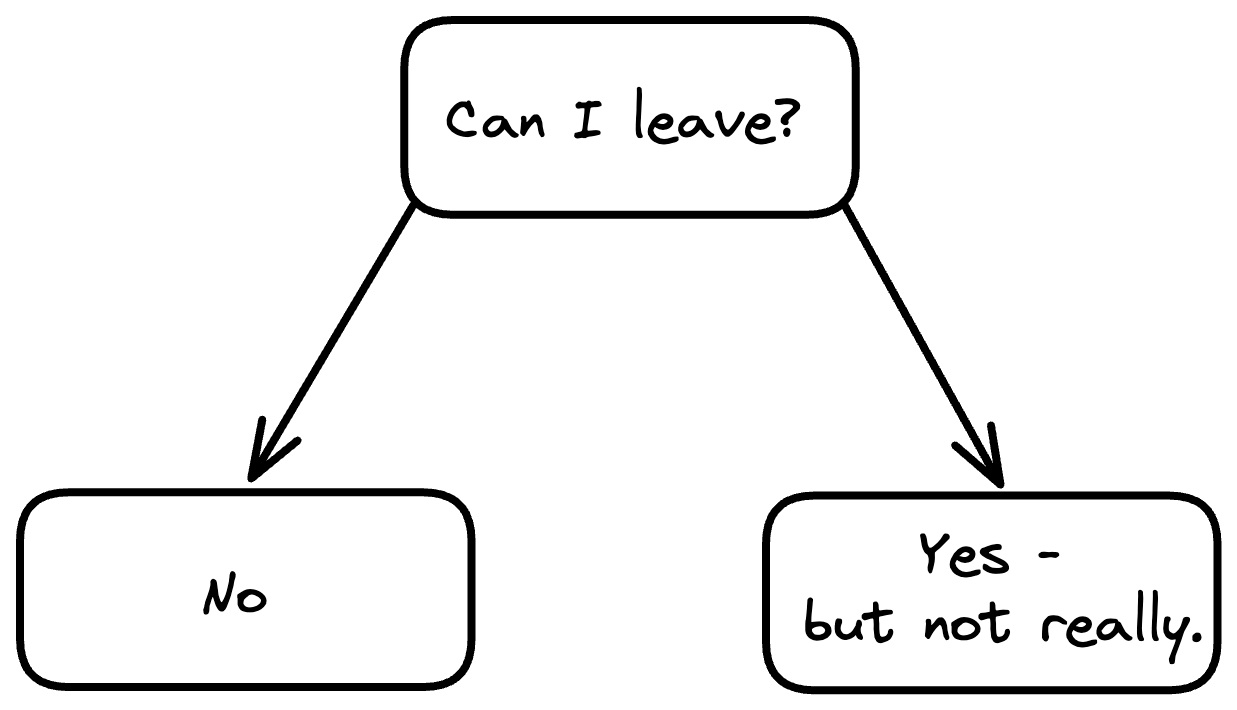
For example, I can always export my data from Twitter or Google, but can I honestly do anything meaningful? I can scroll through endless machine-readable CSVs and marvel at my own witty fodder, but beyond that, there’s not much I can do with it. The goal for any system geared toward user control should be to answer the following questions:
We believe that it all starts with a user being able to meaningfully leave a service.
One of the first core tenets of user control is that, at any time, users should be able to eject from any system or application they don’t wish to use and have complete control over all of their generated data. Whether in the context of a social media platform, a banking website, or even productivity applications, the user, as the sole generator of information, should always be taken care of.
This is one of the cornerstones of the web3 movement regarding assets and identifiers. Your public key is an identifier under your control, and your on-chain activity translates across dapps.
 Rocco
Rocco
Giving users control is not as easy as clicking a button to export data, as it will require various ways of representing different pieces of information that can be useful in other contexts. It will also require industry groups to coordinate and agree upon standard representations of different forms of data. Right now, the rights afforded to users mainly serve the purpose of not drawing the ire of regulators, by allowing users to export poorly formed files to let them know how they are being tracked.
Once granted control in the form of useful data exports and data custody, our goal should be to continually let users leave these existing platforms while granting the expectation that the experience will be nearly the same in a different context.
Thankfully, we’ve reached a point, especially with those working on the fediverse, web3, and more, that looks a lot like this:

Incredible steps have been taken across the space in key management, signing, and more to make this possible. We’ll always continue to commend those that came before us and those we collaborate with now on these complex problems.
However, the next step is the user experience around the control of this information.
Now that we’ve established that the “can I leave” problem should always be answered with “yes,” the next question should be around how much control a user has over said exported information. Our goal as an organization is to never compromise on the user having the ability to take full control over their interactions but also to tip the scale in favor of user experience while we do it. Every organization philosophically aligned with this concept should be building toward this same type of outcome.

If a user could usefully export their data from an app or service but was limited to only using a large tech provider to continue to custody that data, then we haven’t really achieved user control and instead have just shuffled our trust assumptions. When thinking about decentralized data, it isn’t necessarily just about leaving that user at the whim of a decentralized network, but rather, giving the user control to specify where they custody their information and how they present it.
When considering this problem space, the following question should be the core litmus test of user control: can a user kick a custodian out and easily take custody of their own data?
We understand that some users will go with existing providers that they trust, but our goal is to also avoid situations where everyday users have to use complex systems to manage their own information. We want to see a world where a user can always control the governance of their data, specifying anything from a group of custodians to even the server in their basement as to where that data lives.
Additionally, as mentioned earlier, if a user were to ever self-custody their data, we want to avoid the situation where a user is forced to wrangle with a command line to get started.
And instead, have interfaces they recognize, while knowing users are storing and managing their own data:
Finally, now that we have exports that users can command, and custody users can achieve, we have to answer the final question.
Finally, the last question in our for user-controlled data is, “Can a user now take this data under their control to different apps and services and use it there?” Users should be able to opt out of one service and replace it with a competitor.
This would result in a future where tech companies and services compete on user experience, rather than holding user content hostage as their primary competitive edge.
This is demonstratable in the world of social media. Content creators have built personal brand empires across social media platforms, including Twitter, TikTok, Instagram, and more. These content creators are at the mercy of each independent social media platform, without a clear way to export their self-generated content, social graph, and brand relationships if one of those platforms shuts down (or becomes banned, as has recently been a concern with TikTok in the United States). This “profile hostage” situation happens across almost every service we use across the internet, but it requires a radical shift in how we collectively, across every industry, think about consumers’ relationships with companies.
This requires collaboration across public and private sectors to agree on common representations of specific data. User data could be anything from how a post is represented in the context of a user’s social graph, to even a credential linking a Twitter account to an Ethereum account.
At Spruce, we’re working on a lot of these core primitives, and want to build a world where all three questions aren’t just acknowledged, but answered.
If you're curious about integrating Spruce's technology into your project, come chat with us in our Discord:







