

Updates to SpruceID’s Developer Documentation
We've revamped our developer documentation and mobile SDKs to simplify integrating verifiable digital credentials into your apps.
Just yesterday, W3C Decentralized Identifiers were approved to be released as an official W3C Recommendation. As a W3C member organization, we are thrilled by this excellent outcome, and will celebrate it by sharing our favorite ideas about the next evolutions of DIDs that will make them more secure, composable, and friendly to implementers.

A decentralized identifier (DID) is a URI that resolves to a JSON object called a DID document, which describes how to authenticate as the DID’s controller for different purposes. When a service knows that it’s talking to the controller, it can use this fact as the consistent anchor point to construct a decentralized identity, enriching the session with related data referring to the DID such as verifiable credentials (VCs) or any associated information found on a public blockchain.

Where do DID documents come from? Each DID specifies a “DID method” that describes an exact resolution procedure (among other actions) to interpret the DID’s “method specific identifier” and ultimately produce a DID document.

DID methods can retrieve data from a variety of sources: TLS-protected websites, public blockchains, or solely from the method-specific identifier itself. Over the past several years, dozens of different DID methods have emerged in practice, with proponents enthusiastic at how powerful and flexible DIDs can be to bridge disparate trust systems (e.g., Ethereum, GPG, and X.509), and detractors declaring an impending interoperability nightmare, with plenty of headaches for implementers.
However, there is a way we can prevent this impending interop nightmare!
Enter DID method traits: testable properties about DID methods that can help implementers tame complexity and choose the right DID method(s) for their use case. They can be used as requirements revealing which DID methods could satisfy the relevant constraints presented across different use cases.
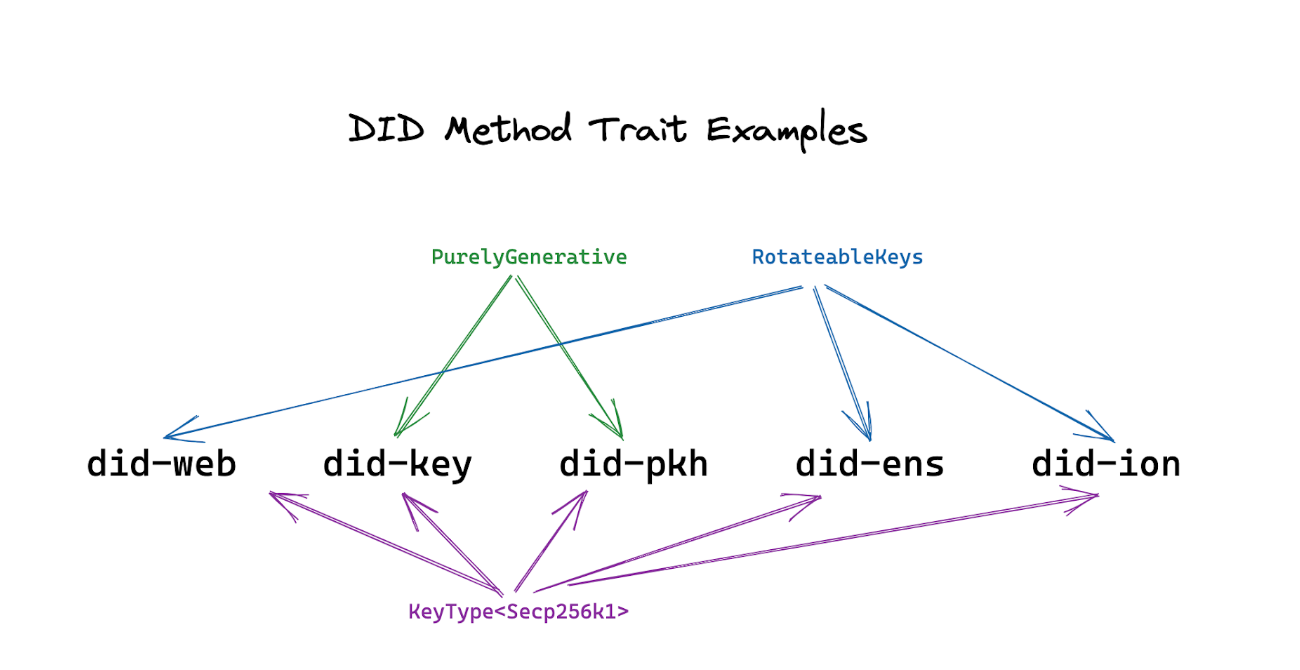
For example, requirements to support certain operations for the NIST Curve P-256, NIST-proposed Curve Ed25519, bitcoin Curve secp256k1 could all be expressed as different DID method traits complete with test suites. Also expressible as DID traits is the guarantee that a DID method is “purely generative,” requiring no storage lookups as in the case of did-key and did-pkh, as opposed to those actively querying a network such as did-web, did-ens, and did-ion.
Finally, there may exist a DID method trait that ensures composability across different DID methods: that one DID may serve as the authentication method for another DID, such as did-pkh for did-ens or did-ion.
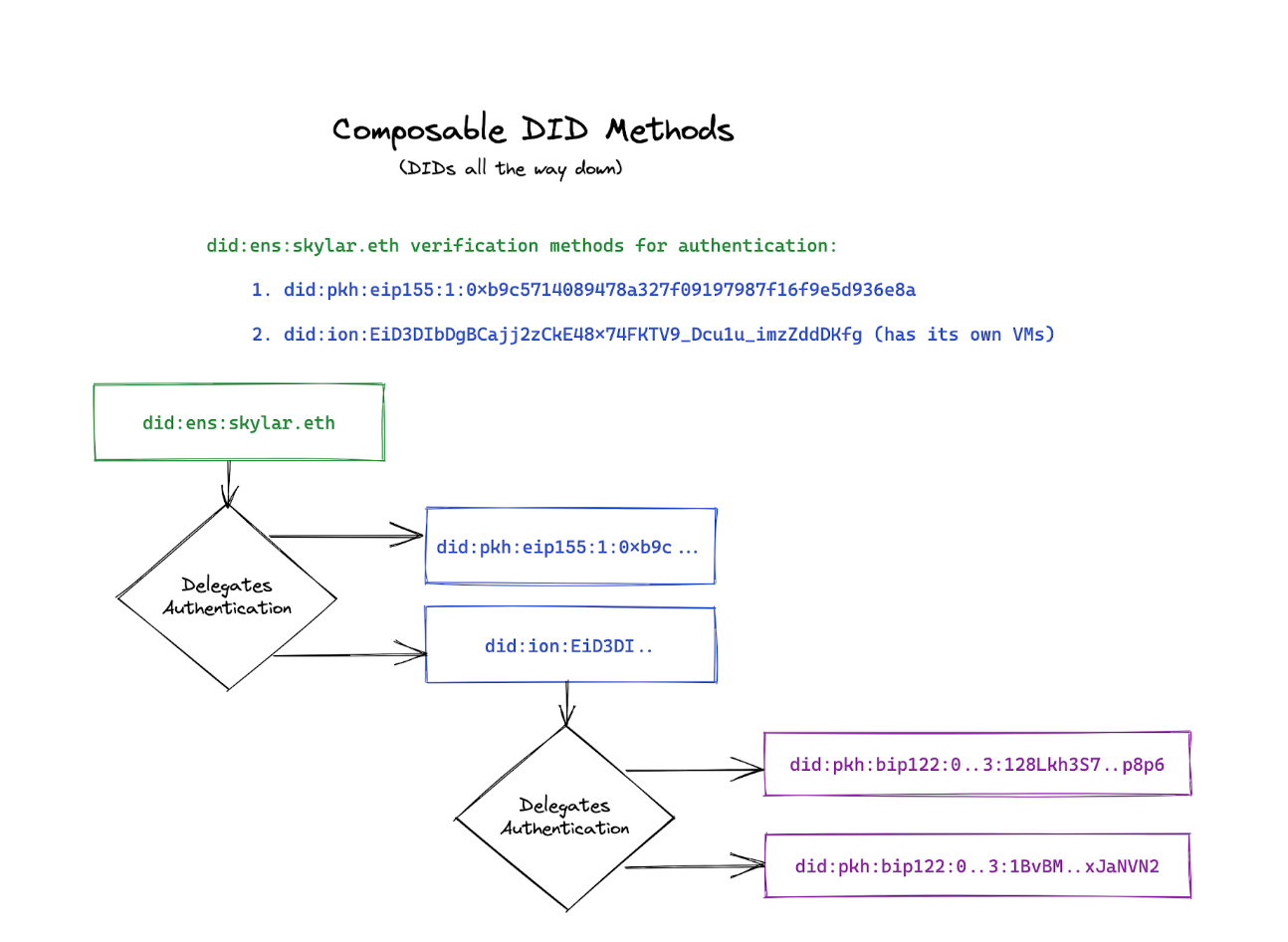
This means that a user can start with an Ethereum account represented as did-pkh, then “upgrade” to a DID method that supports key rotation such as did-ens or did-ion. This helps create a great user experience when using DIDs, as with this approach, users do not need to set up a new decentralized public key infrastructure just to get started.
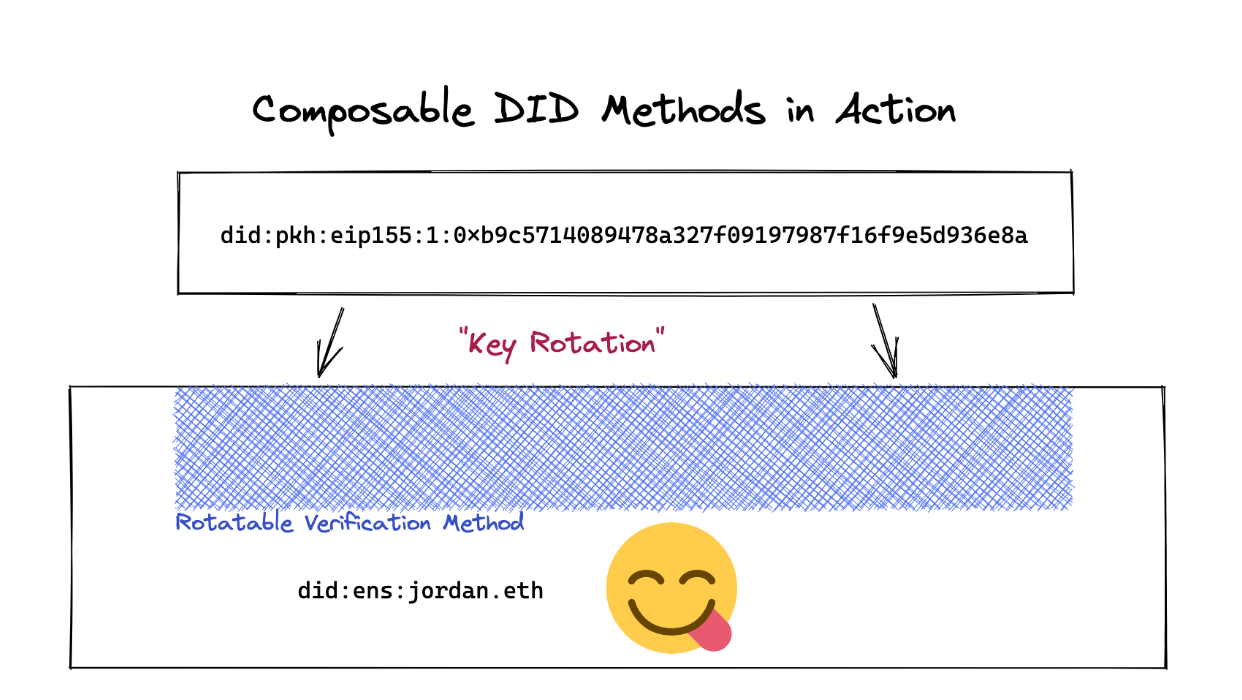
Instead, they can start with whatever key-based accounts they have, leverage the corresponding DID methods, and graft their existing identifier to a more featureful DID method supporting this kind of composability whenever needed.
Previous work has been done on the DID method rubric, which evaluates criteria as wide-ranging as underlying network decentralization, adoption metrics, and regulatory compliance. DID method traits may exist as a subset of possible criteria in the DID method rubric, or as a parallel spec used in conjunction.
I will be writing a paper on DID method traits as my submission to the forthcoming Rebooting the Web of Trust (RWOT) conference in The Hague. If you’d like to collaborate on this, please reach out!
Spruce lets users control their data across the web. If you're curious about integrating Spruce's technology into your project, come chat with us in our Discord:







